

Right now, AI is having a moment — it’s a feature everyone’s curious about, investors and customers included.
However, AI integration is not just a magnet for investors or promotional speak. For many products, successful AI integration is often the only way to solve a problem their customers are facing.
Whatever the reason, the absolute majority of companies are making use of AI today. But the trick is to do it in a way that actually enhances the product instead of bloating it or increasing the development cost.
Key takeaways:
- AI integration requires strategic justification, not trend-following. Successful implementations solve specific, measurable business problems rather than adding AI for competitive positioning alone.
- Healthcare AI projects must prioritize compliance from day one. HIPAA, FDA, and state regulations constrain every technical decision, from architecture choices to data handling protocols.
- Most applications benefit from hybrid AI approaches. Combining pre-trained models with domain-specific fine-tuning typically delivers better ROI than building custom models from scratch.
- Data quality determines AI success more than algorithm sophistication. Projects fail when training data is insufficient, biased, or incompatible with production environments.
- Integration complexity scales exponentially with legacy system dependencies. Custom connectors, data format translation, and API development often represent 40-60% of total project costs.
Understanding AI and its capabilities
Usually, by integrating AI into their digital products, companies mean that they bake one of the following AI technologies:
- Machine learning — algorithms that draw upon data to generate predictions or make decisions (such as predictive analytics and fraud detection).
- Natural language processing — enables apps to understand, make sense of, and generate human language (such as sentiment analysis, text summarization).
- Computer vision — enables apps to analyze images or videos (such as medical image analysis and face recognition).
- Generative AI — gives applications the capability to create text-, image-, or voice-based content based on learnt patterns (such as virtual assistants and AI scribes).
- Hybrid AI — combines AI technologies to complete a task (computer vision detecting lesions + NLP parsing patient history = an AI-based diagnostic tool).
Is it worth integrating AI into your app?
Let us address the elephant in the room: AI integration isn’t always worth investing in. But when your use case is the right fit for the technology (more on this later), making artificial intelligence a part of your solution almost always pays off in the form of:
- Reduced costs — According to McKinsey, generative AI alone can save between $1.4 trillion and $2.6 trillion across various operations through the automation of repetitive tasks.
- Happier customers/users — 80% of consumers are comfortable with personalized experiences, and for most, it’s expected. Granular personalization leads to better customer experience and higher user engagement.
- Competitive edge — In the US, AI startups have locked up $91 billion in funding in Q2 2025, accounting for the bulk of all funding that quarter, and up 11% from last year.
👉 Overall, the benefits of embedding AI models into products differ by industry and specific case. For example, for one of our healthcare clients, we implemented an AI-based solution that alleviated the problem of staff burnout, allowing nurses to automate their daily tasks. The app improved task management efficiency by 40%, reduced procedural errors by 30%, and yielded a 25% increase in productivity for nurses.
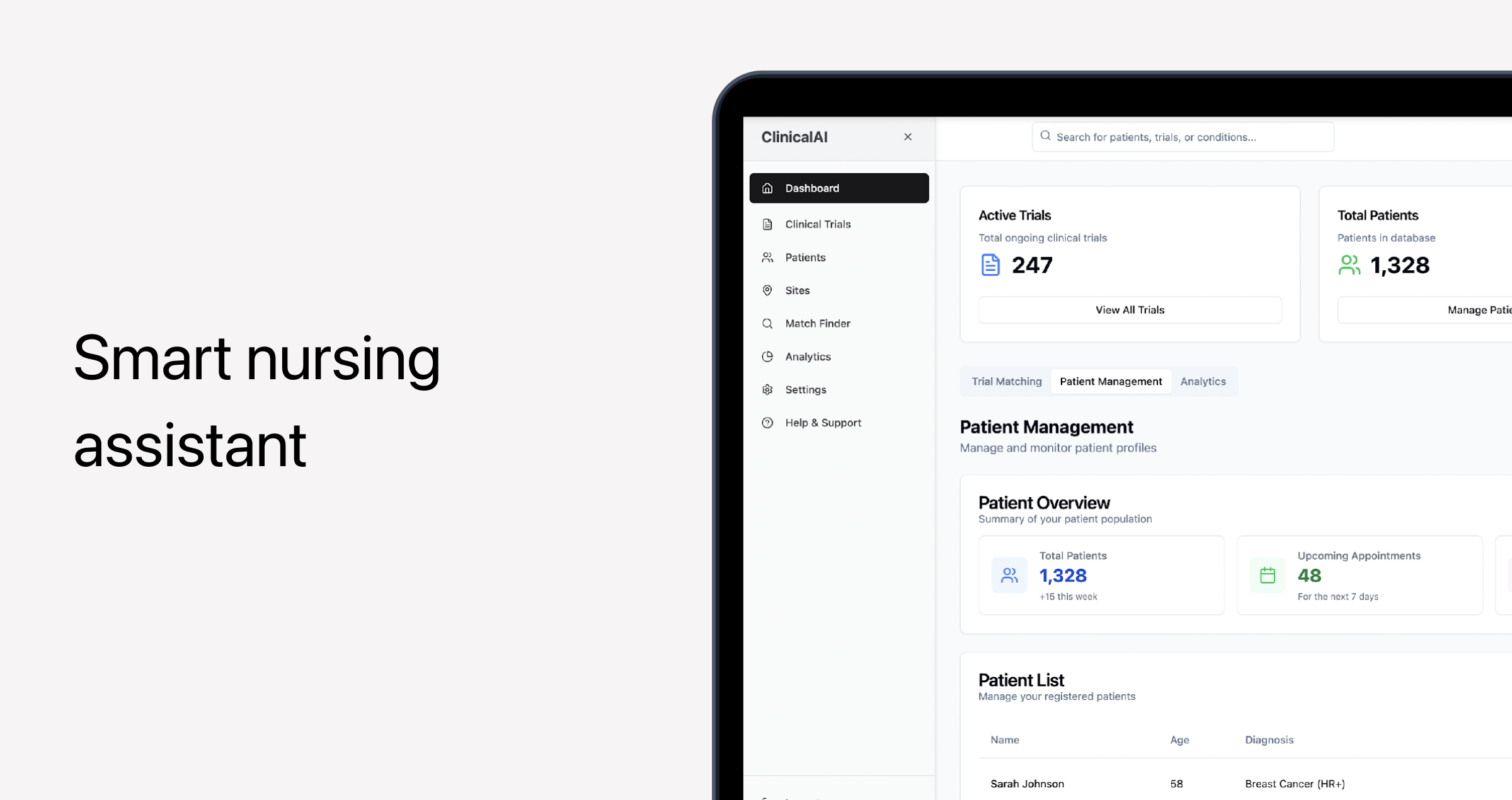
What are common AI use cases in apps?
Based on AI projects we’ve delivered to our clients, our machine learning engineers have noted that high-value AI use cases generally fall into several major categories:
High-volume repetitive tasks
These are the tasks that eat into users’ time and focus, but don’t necessarily require a human to handle them. Claims processing, data logging, and appointment scheduling are prime candidates for AI automation. While AI handles the heavy lifting of daily tasks, the team can focus on tackling complex, high-value issues.
More mission-critical, but also repetitive tasks can also be automated with artificial intelligence. In this case, the human-in-the-loop approach ensures human review of key decisions.
👉 That was exactly the case with one of our projects: the client needed to automate clinical trial matching but didn’t want to trust AI completely with patients’ safety and eligibility. Our developers implemented an advanced clinical trial matching algorithm with the human-in-the-loop guardrails — so every AI suggestion was reviewed by a clinician before finalizing eligibility.
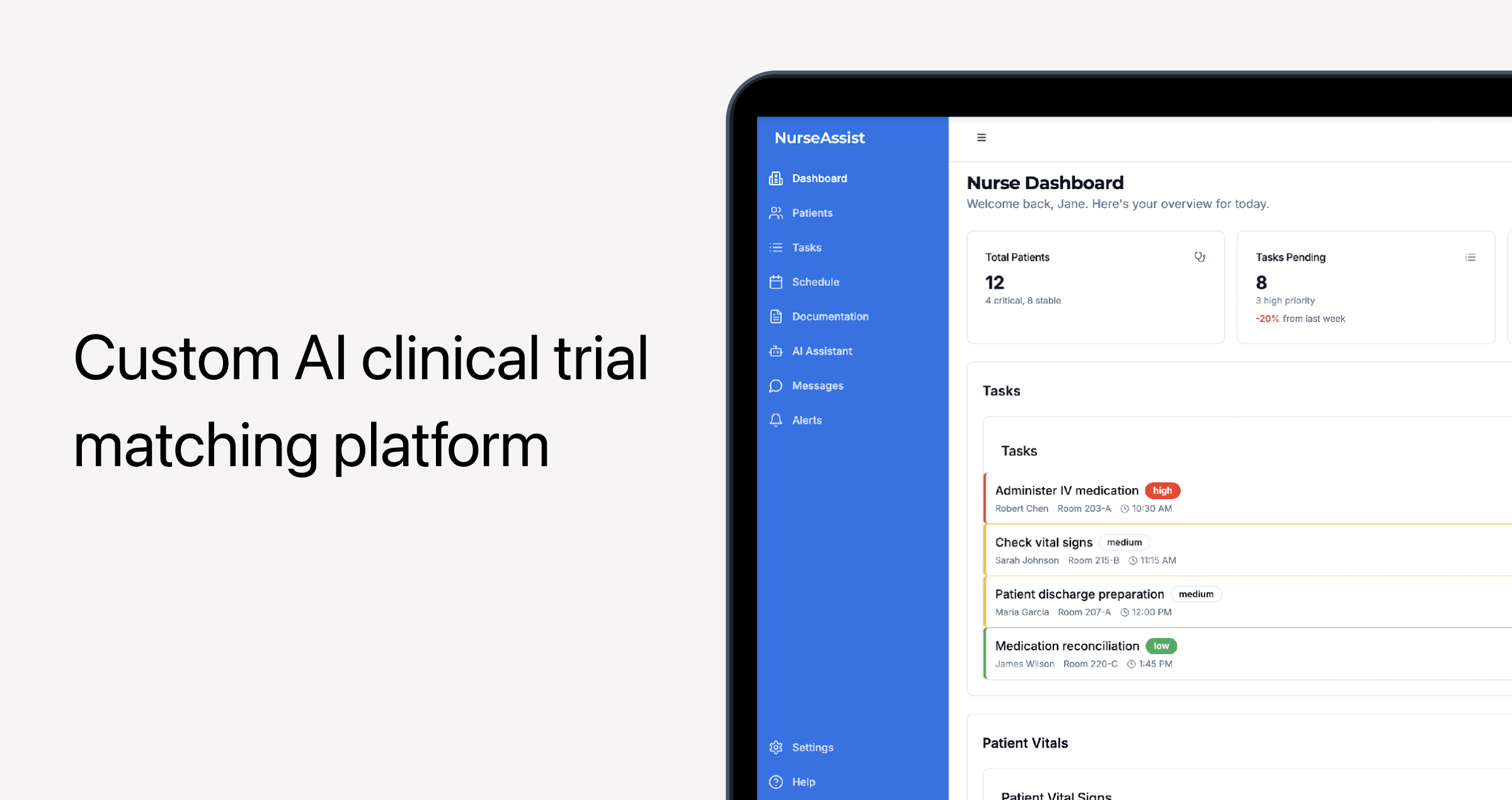
Pattern-rich data environments
If a company has enough available data with enough consistent signals for an AI model to work with, the use case can be safely classified as fit-for-AI. Examples of such use cases include e-commerce recommendations, predictive maintenance solutions, healthcare diagnostics, and fraud detection.
Within such environments, AI models can often break down different data modalities to form a complete picture, which is the case with healthcare diagnostics that require the analysis of medical images, lab results, and other types of data.
Scalability needs
Whenever a company has spikes in demand or user activity, AI can step in to handle the surge without adding proportional human or infrastructure costs. Let’s take fraud detection or risk scoring as an example: companies can replace heavy batch jobs with AI. Smart models don’t wait for end-of-day runs — they process transactions in real-time and thus reduce resource usage during peak times.
Real-time decision intelligence
Often, apps need to make quick, smart decisions on the fly, right when the data flows in — in situations like approving a loan or pulling up the perfect product. That’s a classic AI-fit use case, because the AI system can process heaps of data in seconds and suggest the best action immediately.
Steps to integrate AI into your app: step-by-step blueprint from an AI team
So how can you transform your product into an AI solution without bloating the costs? You need to start with the “why”.
Step 1: Define clear business goals and other basics
This step includes the following milestones:
Prove the feasibility
First things first, you need to validate that smart technologies are the right solution to your business problem. For example, if the hospital only has a few departments and predictable shift patterns, a simple rule-based scheduling tool will suffice. However, if the mentioned hospital grapples with dozens of departments, dynamic patient loads, and complex staffing rules, machine learning models are right up its alley.
In terms of technical feasibility, you need to make sure your existing technology stack and data are AI-ready, and whether your idea can be implemented at all.
Solidify your business goals
If AI integration is what you need, we recommend using the "Jobs to be Done" framework to nail down the goal you want to achieve with AI:
✅ ”Add AI to the hospital scheduling system.”
❌ “Add AI to cut the time nurses spend on administrative charting by 25% in the next quarter.”
Align with regulatory compliance
Regulatory obligations are also something companies should account for early on if they want to avoid costly rebuilds down the road. In regulated industries such as healthcare and fintech, AI-powered solutions should not only be smart but also compliant with HIPAA, GDPR, or other local data protection laws.
Regulatory requirements impact every aspect of AI development and integration — from architecture choices and data handling to the level of model explainability.
Step 2: Data collection and preparation
Data scientists assess the data quality, quantity, and relevance to see if your internal data is enough to train the model and achieve its high accuracy and reliability. Training data gets cleaned up, with data engineers filling in missing values, removing duplicates, and standardizing formats. If you’re developing for highly regulated industries, sensitive data like PHI also needs to be anonymized or de-identified before it can be used.
Sometimes, existing data alone falls short of providing enough context for model training. In that case, data engineers supplement the training material with external datasets or synthetic data as part of the data preparation process.
For example, when we were building a clinical decision support tool for one of our clients, the available internal lab records couldn’t cover rare conditions. Our team ended up enriching the dataset with publicly available medical image repositories to train the model for uncommon patterns.
Step 3: Selecting or developing AI models
Should you use a third-party AI API or build your own model? From our experience, around 80% of apps don’t need custom models. But there’s a catch:
- Go custom if: you have a truly unique problem, massive proprietary data, and strict latency/compliance needs that APIs can't meet (for example, a tool for detecting early signs of sepsis).
- Go with pre-built if: the task you’re solving with AI is generic, such as sentiment analysis or object detection.
Often, companies opt for a hybrid approach to strike a balance between model accuracy and deployment costs. The team takes a fit-for-purpose open-source model, such as BioBERT for medical text, and fine-tunes it based on the proprietary data.
💡If a pre-trained model achieves 99% of your target accuracy, don’t build custom. Keep in mind that the target accuracy varies for each use case. For healthcare, teams should aim for 90-95%+, while in less high-stakes industries, the accuracy of 80-85% is acceptable.
Step 4: AI model training and validation
Next, the AI development team feeds the prepared datasets into the algorithm and calibrates it for optimal performance. The entire training process involves multiple iterations, during which the team dynamically adjusts the hyperparameters until the model meets performance benchmarks.
However, training alone is not enough. To make sure the model generalizes well to real-world contexts, AI developers have to validate it by running it on a completely new dataset that wasn’t used for training. This allows the team to assess the model’s actual performance metrics, such as accuracy, precision, recall, F1 score, or domain-specific metrics like sensitivity in healthcare.
💡 Along with training for the happy path, the development team must stress-test the model for edge cases to ensure it won’t fail under rare or high-risk scenarios. Checking regulatory compliance is also a vital step prior to AI integration.
Step 5: Integration of AI models via APIs or embedded models
How to integrate AI into an app? You have three options:
API-based integration
Instead of planting the AI model directly inside the app, many companies expose it via REST or GraphQL APIs. In this case, the model is available remotely. The app sends the data to the API, while the model processes the data and sends it back in real time.
We recommend choosing this approach if:
- You want faster deployment.
- You don’t have the infrastructure for the local hosting of heavy AI models.
- You plan to update the AI logic without tweaking the main app.
Embedded models
Within this AI integration approach, the model is woven directly into AI applications or their backend infrastructure. In this case, the latency is minimal, and the app can work offline. However, local models require sufficient CPU/GPU and memory to run, so the trade-offs lie in hosting costs and the complexity of scaling.
The embedded AI integration approach is suitable for the following scenarios:
- Your app needs to process data at high speed or in real time.
- You need your app and the AI features to work even when the internet connection is spotty or unavailable.
- When data privacy and compliance are critical (the data stays on the device).
Based on our experience, healthcare devices and edge computing solutions are the most common use cases for embedded AI integration.
Hybrid approach
In some cases, it’s worth using a combination of embedded and API-based integrations. More lightweight models can be plugged directly into the app to handle common tasks, while heavier computations and rare scenarios are handed over to a cloud-based API. For example, a healthcare app can perform routine scans based on local anomaly detection — and send complex or rare cases to a cloud model for deeper analysis.
Step 6: Testing and quality assurance specific to AI functionalities
AI-specific QA doesn’t boil down to just checking whether the AI-powered app works in general. It focuses on the AI component of the application, making sure it’s reliable, accurate, and safe to use. The AI development team usually runs the following types of checks to validate the AI system:
- Functional testing — checking whether the AI outputs match expectations for typical inputs.
- Edge-case testing — seeing how the model fares in rare or extreme scenarios.
- Performance testing — measuring latency, throughput, and resource consumption.
- Bias and fairness testing — examining the model for demographic or feature biases.
- Security validation — making sure the sensitive data doesn’t slip through the cracks and that the model is protected against data poisoning or model theft.
💡When the team deals with sensitive data like Protected Health Information, they can use a completely synthetic dataset or combine it with de-identified real-world data to test the system without jeopardizing data privacy.
Step 7: Deployment and monitoring AI performance in production
After the model is put into production (we recommend staged releases), the team should continue to monitor it to prevent model drift and track key metrics. In some industries, audit logs of AI decisions must be part of the monitoring process.
As for data retraining, not all applications need it to be constant. Usually, a well-set pipeline triggers retraining only when performance drops below a specific threshold or new data flows in. In stable use cases, like medical imaging or defect detection, retraining can be scheduled quarterly or biannually.
Technical considerations for incorporating AI
There’s a lot that goes into AI development and integration. While a lot depends on the specific project, some points resurface in almost every integration instance.
Backend architecture and scalability
- AI workloads, especially those with inference at scale, require robust backend systems that can withstand demand fluctuations without collapsing.
- Microservices architecture is a good choice for AI integration, because AI models can be deployed as standalone services (just make sure you aren’t over-optimizing).
- Load balancing, paired with autoscaling via Kubernetes, Docker, or serverless platforms, will ensure that AI predictions remain accurate even when users utilize the app heavily.
Model training vs. inference
- The team must plan upfront how the training pipeline interacts with the inference pipeline, because if they mix in the wrong way, this can result in downtimes, slow responses, and even outdated predictions.
- Training is computationally intensive, which is why it’s usually done offline. It doesn’t need to be tied directly to your app’s runtime.
- To keep the UX smooth, the AI integration team needs to optimize inference latency through quantization, pruning, or hardware acceleration.
Real-time vs. batch processing
- Real-time processing is not a universal requirement for AI-powered features. It’s needed only when quick decisions matter and when the minimal latency is critical.
- Batch processing is cheaper and does the job for non-urgent workloads, such as predictive maintenance.
Cloud AI services vs. custom ML pipelines
- Google Cloud AI, Microsoft Azure AI, AWS, OpenAI, and other cloud-based services allow the team to quickly deploy AI solutions with pre-trained APIs and managed infrastructure. This approach lends itself well to rapid MVPs and generic tasks, such as speech-to-text.
- Custom ML pipelines come into play when companies have proprietary data, regulatory/data privacy obligations, or domain-specific accuracy that off-the-shelf APIs fail to provide. This approach is more expensive than the cloud-based one.
Mobile integration challenges
- To run models on-device, teams need to lay down a lightweight architecture like MobileNet and TinyML — or quantized versions of larger models.
- Since mobile hardware comes with certain CPU/GPU/TPU limits, it naturally places restrictions on the model size and inference speed. To make up for it, AI developers need to strike the right balance between accuracy, latency, and battery consumption.
- When the model is embedded right into the app, any update triggers a new app release cycle unless you set up dynamic model downloads.
Compliance and security considerations for regulated industries
When you’re developing AI tools for sectors like healthcare, finance, or insurance, your AI strategy has to combine innovativeness with compliance. As we’re primarily focused on the healthcare industry, we’ll discuss the nuances of this sector. However, the same concept applies to any other regulated industry; just make sure to study the specific regulatory bodies that govern it.
HIPAA, GDPR, and other regulatory frameworks
In healthcare, there are global and location-specific regulatory frameworks:
- HIPAA (US)— Any AI system that stores, processes, or transmits patient data must be equipped with strict audit trails, access controls, and encryption.
- GDPR (EU) — AI must respect data subject rights, including transparency, portability, and the right to explanation for automated decisions (meaning that no ‘black-box’ AI models are allowed).
- FDA and MDR (for medical devices) — Often, AI-powered medical devices are classified as software-as-a-medical-device (SaMD). This means that the AI model must be developed and integrated according to a structured, documented development process, backed by the ISO 14971 and ISO 13485 standards.
Bottom line: Every data pipeline, model update, and inference must be compliant when developing for healthcare.
💡There are also industry-agnostic frameworks such as the EU AI Act and the NIST AI Risk Management Framework, which provide blueprints for developing safe, compliant, and auditable AI systems across sectors.
Data anonymization and user consent
To minimize the risk of regulatory violations, AI integration teams should lead with the “privacy by design” approach:
Anonymize sensitive data
If training datasets contain sensitive data such as personally identifiable information (PII), AI engineers must remove it so that it can’t be traced back to an individual. Teams can anonymize data using several techniques, such as masking, pseudonymization, and others.
However, no matter how well that sensitive data is kept under wraps, it’s still important to minimize its exposure. That’s why developers keep the amount of sensitive data in datasets to a minimum — a technique called data minimization.
Implement strict consent management
Under GDPR and other regulations of such caliber, companies can’t gather, store, or process personal data without a legal basis. That’s why companies must obtain explicit and documented consent from individuals for the use, storage, and sharing of their data.
Secure data handling and model explainability
A comprehensive data security strategy is another pillar of derisked and compliant AI integration.
Data security measures
Secure data handling in regulated industries includes the following list of measures:
- Encrypting data at rest and in transit
- Limiting access to sensitive data based on roles (RBAC)
- Logging all data access and modifications for reporting
- Using a compliant, certified data storage for sensitive datasets
- Segmenting data into sensitive and non-sensitive categories, and others.
However, it’s not enough to secure just the data. The AI model must handle that data in a secure and explainable way as well.
XAI approach to AI integration
While accuracy of the AI model is crucial, its auditability, transparency, and interpretability are even more so — especially when it comes to regulated industries.
This is where the XAI approach comes into play. In short, this approach focuses on achieving the following:
- Traceability of AI decisions — Every prediction the AI inside the app makes must be backed by a clear, auditable chain of inputs and logic.
- Interpretable outputs — Users should be able to understand why the AI made a particular recommendation.
- Bias detection and mitigation — Explainable models are easier to check for systematic unfairness.
- Support for human-in-the-loop review — Explainability also supports human oversight, allowing human decision-makers to validate AI outputs before acting on them.
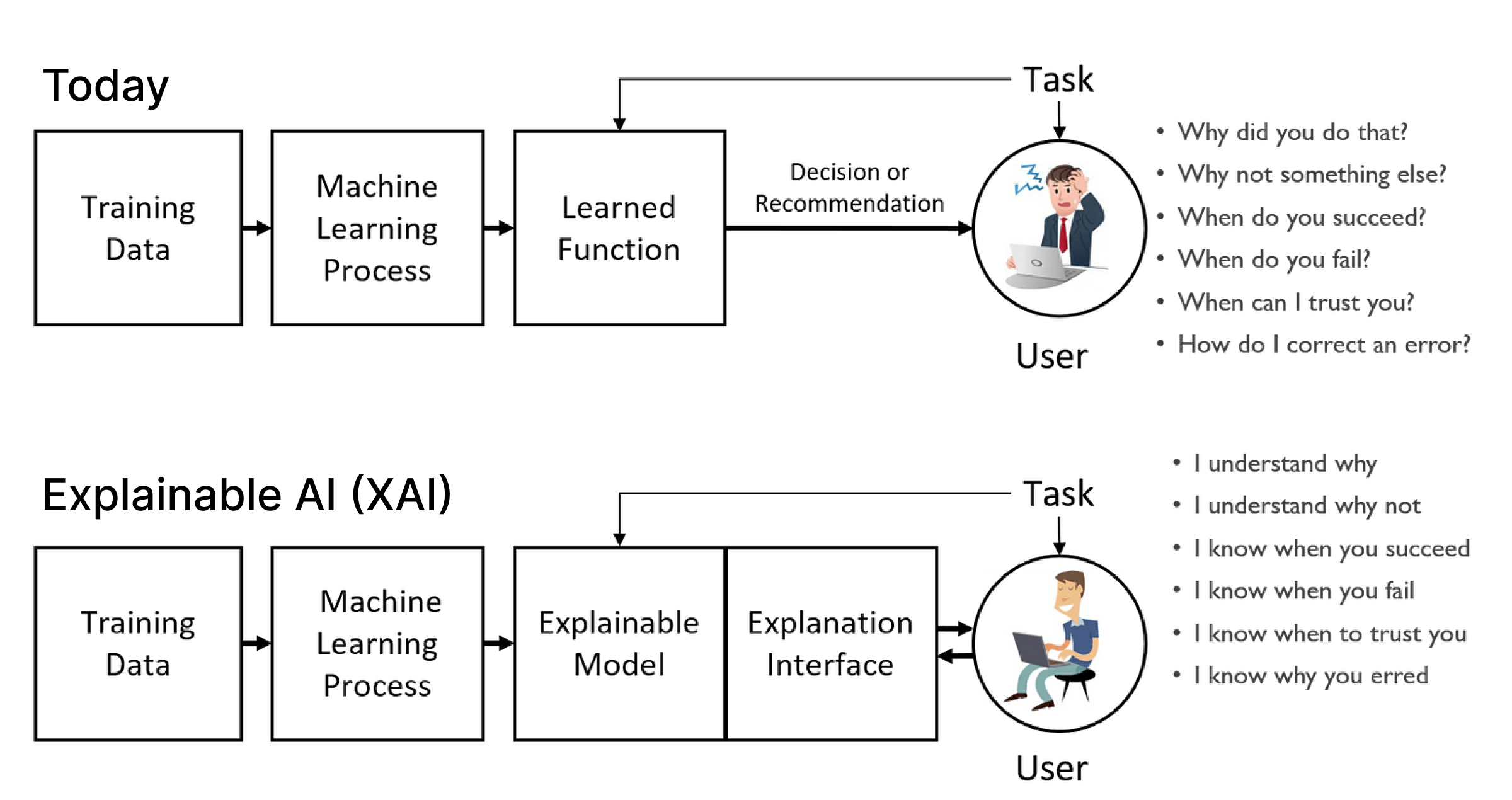
Common AI integration challenges 99% of projects face
Many companies approach AI integration with a myopic understanding of what that entails. They envision the result, without fully comprehending the infrastructure, processes, and governance needed to make that integration sustainable. The reality is that they need to align data pipelines, compliance, and business workflows in a way that doesn’t collapse under real-world pressure and takes care of long-term concerns.
Limited or biased data
Models are only as good as the data on which they’re trained. Poor-quality data or insufficient training data will impact AI outputs, leading to flawed predictions, unreliable recommendations, and even unsafe decisions.
In some projects, high-quality, labeled data is especially hard to obtain. This is the case with medical imaging data analysis: high-quality MRI, CT, or histopathology scans are scarce because they’re costly to collect, need expert labelling, and are subject to strict privacy regulations.
Risk mitigation strategies: data augmentation, synthetic data generation, federated learning, bias mitigation.
Model drift and performance over time
As the underlying data or environment changes, so do AI models. When the statistical properties of incoming data begin to diverge from those of the original training data, the model drifts — meaning it becomes less accurate, less reliable, or even unsafe in critical applications.
Risk mitigation strategies: continuous monitoring frameworks, periodic retraining with updated datasets, combined with explainable AI techniques to investigate the reason behind model drift.
Integration with legacy systems
Integration complexity increases significantly when AI tools must connect with legacy systems. In this case, AI developers face the triple challenge of incompatible data formats, fragmented databases, and systems that were never designed to support AI-driven decision-making.
The catch is that outdated systems are often stale, built on last-century architectures, and lack the APIs or data pipelines needed for smooth AI integration and seamless data exchange. Unfortunately, there are no shortcuts to solve this challenge — engineers must spend extra time creating custom connectors or workarounds.
Risk mitigation strategies: middleware or integration platforms, standardized APIs, modularized AI components for easier plug-and-play deployment, supported by parallel pilot programs.
Reliance on third-party services
Whenever teams tap into cloud-based AI platforms or pre-trained models, they introduce dependencies that can backfire in the future. Whether that’s vendor lock-in, cost volatility, or limited insight into the model internals, owned AI development and integration tools can disrupt your AI workflows.
Risk mitigation strategies: contract-level SLAs, multi-vendor strategies, and hybrid approaches that combine in-house and third-party AI capabilities.
Cost of AI integration
The costs of AI integration vary by project, depending on the infrastructure and data requirements, the complexity of the solution, the complexity of integration, and the regulatory burden. Below, our team has provided a breakdown of the main cost drivers and their typical ranges, based on the project scope and scale.
| Cost category | Small project (Prototype/pilot) | Medium project (functional-area project) | Large project (Enterprise-grade) |
|---|---|---|---|
| Infrastructure (cloud compute, servers, storage, GPUs) | $5K - $20K | $20K - $100K | $100K - $500K |
| Data collection and labelling (purchase of datasets, annotation, cleaning) | $3K - $15K | $15K - $50K | $50K - $200K |
| AI development and integration (data scientists, ML engineers) | $10K - $50K | $50K - $200K | $200K - $1M |
| Integration and deployment (engineers, DevOps, QA, custom connectors) | $5K - $25K | $25K - $100K | $100K - $500K |
| Maintenance and retraining (retraining, model drift monitoring, bug fixes) | $2K - $10K/year | $10K - $50K/year | $50K - $200K/year |
| Risk mitigation and compliance | approx. 10-20% of total cost | approx. 15-25% of total cost | approx. 20-30% of total cost |
| Third-party services and APIs | $1K - $5K | $5K - $20K | $20K - $100K |
| Total | $28K - $150K | $143K - $650K | $624K - $3.2M |
Notes on the costs of integration:
- Small projects are typically pilots that may use pre-trained models and cloud services to bring down the costs.
- Medium projects are full-scale solutions that incorporate custom models and are designed to plug into existing workflows — with moderate data collection and labeling required.
- Large projects refer to enterprise-wide AI based on custom model development and designed to be integrated across multiple systems.
How to save costs on AI integration
Here are common data-saving techniques that companies can apply without undermining the solution’s quality:
- Start with one high-impact use case that requires limited datasets to test feasibility.
- Leverage pre-trained or reusable models.
- Automate data labelling where possible.
- Build AI components as plug-and-play modules that can be reused across teams.
- Implement MLOps (pipelines, monitoring, retraining schedules) to prevent tech debt.
Conclusion
Integrating AI may look simple on the outside, but more often than not, it’s a complex project in disguise. You need to align infrastructure, data pipelines, compliance, and workflows into a sustainable ecosystem that can scale without incurring huge retraining costs.
Having an experienced AI app development team on board can save you months of trial and error. A seasoned tech partner brings not just technical expertise, but also the domain knowledge necessary to tackle industry-specific challenges, such as compliance. Nowhere is this more critical than in healthcare, where data privacy, explainability, and clinical accuracy are non-negotiable.
Since 2011, Orangesoft has been helping global startups and established companies deliver AI-powered digital products that not only prioritize usability but also meet compliance standards, including HIPAA, FDA, GDPR, and ISO certifications.
If you need help upgrading your product with AI or would like a rough estimate, please reach out to our team.